
How to merge multiple output files from MapReduce or Spark jobs to one?
January 13, 2021How to check size of a directory in HDFS?
January 18, 2021Broadcast Hash Join in Spark works by broadcasting the small dataset to all the executors and once the data is broadcasted a standard hash join is performed in all the executors. Broadcast Hash Join happens in 2 phases.
Broadcast phase – small dataset is broadcasted to all executors
Hash Join phase – small dataset is hashed in all the executors and joined with the partitioned big dataset.
Broadcast Hash Join doesn’t involve a sort operation and it is one of the reasons it is the fastest join algorithm. We will see in detail how it works with an example.
Do you like us to send you a 47 page Definitive guide on Spark join algorithms? ===>
Example
spark.sql.autoBroadcastJoinThreshold – max size of dataframe that can be broadcasted. The default is 10 MB. Which means only datasets below 10 MB can be broadcasted.
We have 2 DataFrames df1 and df2 with one column in each – id1 and id2 respectively. We are doing a simple join on id1 and id2.
scala> spark.conf.get("spark.sql.autoBroadcastJoinThreshold")
res1: String = 10485760
scala> val data1 = Seq(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50)
data1: Seq[Int] = List(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50)
scala> val df1 = data1.toDF("id1")
df1: org.apache.spark.sql.DataFrame = [id1: int]
scala> val data2 = Seq(30, 20, 40, 50)
data2: Seq[Int] = List(30, 20, 40, 50)
scala> val df2 = data2.toDF("id2")
df2: org.apache.spark.sql.DataFrame = [id2: int]
Note that you can also use the broadcast function to specify the dataframe you like to broadcast. And the syntax would look like – df1.join(broadcast(df2), $”id1″ === $”id2″)
scala> val dfJoined = df1.join(df2, $"id1" === $"id2") dfJoined: org.apache.spark.sql.DataFrame = [id1: int, id2: int]
When we see the plan that will be executed, we can see that BroadcastHashJoin is used.
scala> dfJoined.queryExecution.executedPlan res2: org.apache.spark.sql.execution.SparkPlan = *(1) BroadcastHashJoin [id1#3], [id2#8], Inner, BuildRight :- LocalTableScan [id1#3] +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint))) +- LocalTableScan [id2#8] scala> dfJoined.show +---+---+ |id1|id2| +---+---+ | 20| 20| | 20| 20| | 30| 30| | 40| 40| | 40| 40| | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 50| 50| +---+---+
Stages involved in Broadcast Hash Join
As you can see below, the entire Broadcast Hash Join is performed in a single stage. Which means no shuffle is involved.
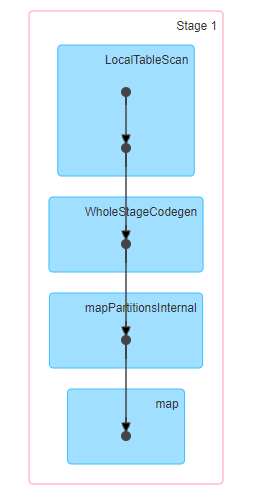
Internal workings of Broadcast Hash Join
There are 2 phases in a Broadcast Hash Join – Broadcast phase and Hash Join phase
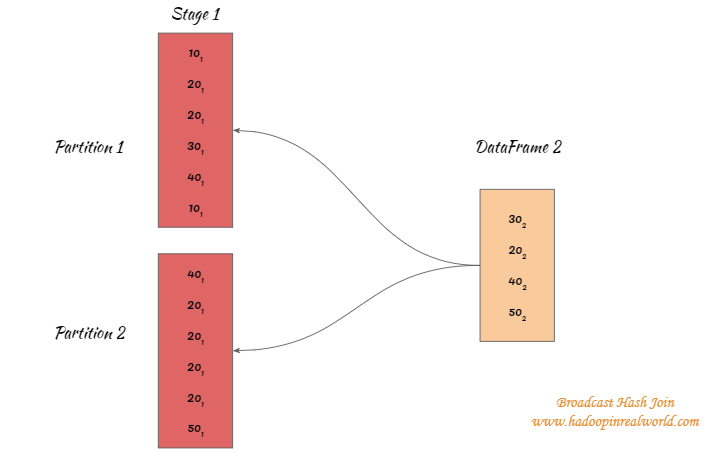
Broadcast Phase
Let’s say the big dataset is divided into 2 partitions and this means we will have 2 separate tasks assigned to process the partitions.
The smallest dataframe between the two dataframes will be broadcasted to the executors processing both the tasks.
20(1) means it is from DataFrame 1 and 20(2) means it is from DataFrame 2.
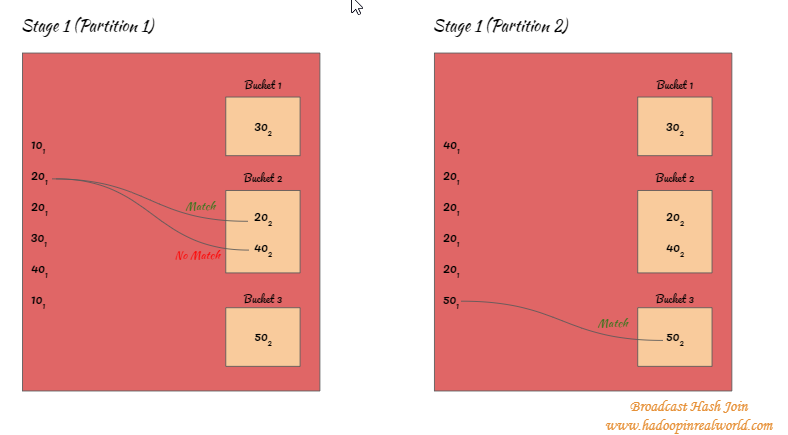
Hash Join phase
- The small dataset which was broadcasted to the executors will be hashed by key in to buckets
- In the below example key 30 is assigned to bucket 1 so anytime we encounter a record with key 30 it will be assigned to bucket 1. 20 and 40 are assigned to bucket 2. 50 is assigned to bucket 3.
- Once the small dataset is hashed and bucketed, keys from the big dataset will be attempted to match ONLY with the respective buckets. For eg. 20(1) from big dataset will be hashed and will be mapped to bucket 2. So with Hash join, we will only attempt to match the keys for 20(1) with all keys inside bucket 2 and not on any other buckets.
- Steps 2 and 3 are executed on all partitions in the stage for all records in the big dataset.
As we have seen Broadcast Hash Join doesn’t involve a sort operation.
When does Broadcast Hash Join work?
- Broadcast Hash Join is the fastest join algorithm when the following criterias are met.
- Works only for equi joins.
- Works for all joins except for full outer joins.
- Broadcast Hash Join works when a dataset is small enough that it can be broadcasted and hashed.
When Broadcast Hash Join doesn’t work?
- Broadcast join doesn’t work for non-equi joins
- Broadcast join doesn’t work for full outer joins
Broadcast Hash Join doesn’t work well if the dataset that is being broadcasted is big.
- If the size of the broadcasted dataset is big, it could become a network intensive operation and cause your job execution to slow down.
- If the size of the broadcasted dataset is big, you would get an OutOfMemory exception when Spark builds the Hash table on the data. Because the Hash table will be kept in memory.
Interested in learning about Broadcast Nested Loop Join in Spark? – Click here.

4 Comments
[…] Interested in learning about Broadcast Hash Join in Spark? – Click here. […]
[…] Check this post to understand how Broad Hash Join works. […]
[…] Check this post to understand how Broad Hash Join works. […]
[…] How does Broadcast Hash Join work in Spark? […]