

Schema Registry & Schema Evolution in Kafka
January 11, 2020
How To Catch Malware Using Spark
May 18, 2020Considering building a big data streaming application? You have come to the right place. This is a comprehensive post on the architectural and orchestration of big data streaming pipelines at industry scale. With a plethora of tools around, it can quickly get out of hand the number of tools and the possible use cases and fit in the overall architecture. I have personally been in a position where I have felt each tool was equally efficient, at least that’s what you feel when you read their own documentation. Upon reading this post you should be able to understand the various components involved in building an efficient streaming pipeline and you should be able to map the tools to the architecture component it belongs to and evaluate with other competitive tools available in the market.
If you are looking for a real world example, check out our Spark Developer In Real World course. We have an end to end project Streaming data from Meetup.com with Kafka & Spark Streaming
Why Streaming?
Businesses want to get insights as quickly as possible and do not want to wait for a day, like before, to bring up a report to understand what happened till yesterday. They require a more proactive approach that can help to act immediately when something significant happens and also to prevent the system from any faults/downtime before it occurs. Imagine you are buying some product from an e-retailer and you have gone till the point to make payment and something happened that caused the payment not to go through successfully. At that very moment, you are having a second thought about whether to buy the product now or later. Suppose, if the business is getting a report of this occurrence next day, it would not be of much use for them as the customer would have already bought it from somewhere or decided against it. This is where real-time events and insights come in. If it were a real-time report, the team would have called up the customer and made the purchase by offering some discounts, which in turn would have changed the mind of the customer.
Architecture
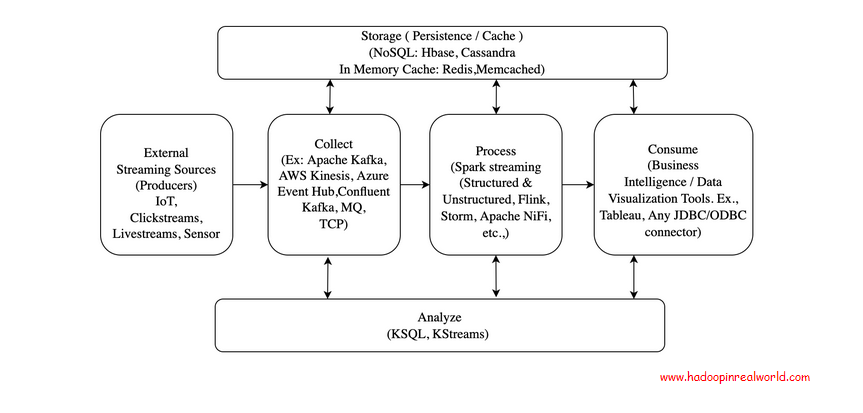
External Sources
External sources are the producers of events. Events are facts that have happened. Events are immutable and any changes to the event would be another event that will get sent after this event.
Some examples of events could be:
- Transactions such as ATM/POS – that happened at a specific time.
- Customer alert preference changes can be captured in real-time and then accordingly alerts or notifications are sent.
- Courier alerts and tracking can be done at real time and notifications can be sent across to the customer.
Like what you are reading? You would like our free live webinars too. Sign up and get notified when we host webinars =>
Collect
Collection is the first and foremost process in any streaming architecture. Data is collected into the streaming platform using the method called ingestion. Queues are primarily used as a means to collect events.
Technologies
There are few technology options to choose from when we collect data. Here are the most prominent ones.
Kafka
Kafka is an open source distributed resilient event orchestration platform that is widely used for capturing real-time events. Kafka works on a publisher-subscriber pattern where the source systems can publish events to the Kafka topic at constant rate and any number of subscribers can subscribe to the topic in Kafka and process those events. It decouples both producers (publishers) and subscribers (consumers) that will enable both to act independently of each other.
Message Queues (MQ)
MQs are primarily JMS Queues that are used to send events. The streaming platform would require a listener to connect to MQ server and pull messages. Establishing socket TCP mode of transportation is another means of sending events. These types of event transportation is quite common for ATM POS transactions.
Amazon Kinesis
Amazon Kinesis is an event streaming offering from Amazon Web Services cloud. Conceptually both kafka and kinesis have a lot of similarities. Behind the scenes, the infrastructure is managed by AWS and hence it is highly scalable and reliable for sources that require high performing streaming interfaces like IoT, etc. AWS has also released AWS Managed Kafka recently for companies that would want to stick to kafka but in cloud.
Azure Event Hub
Azure event hub is a big data streaming platform and event ingestion service offered by Microsoft Azure. Azure Event Hub (AEH) can receive and process millions of events per second and has rich connections to other components of Azure infrastructure. Event hubs are fully managed Platform As A Service (PAAS) component that requires only minor configuration and management overhead from customers. Industries use Event hubs to ingest and process streaming data if they have Microsoft Azure.
Things To Note
Involves system-to-system connection. Network latency, fault tolerance to be built in especially for TCP mode of communication.
- Kafka transports messages in byte format. Industry practice is to transfer messages in Avro format in Kafka and maintain supporting schema in schema registry for schema evolution.
- If the collection component does not have inbuilt persistence like Kafka, then explicit storage must be done to avoid loss of events.
Process
The business events/messages as it is may not add value to the end customers or consumers. The events implicitly mean the occurrence of something significant from the business perspective.
Applications
In a typical home loan application process, an event can be triggered as soon as the credit check for the application is approved/rejected. In online checkout, an event could be triggered if the customer reached the payment step or just before but has not completed the payment.
The aforementioned events are a significant occurrence in the journey of the customer from the application standpoint. These will trigger different conversations that the companies need to have with the customers.
Technologies
Every time a raw event is triggered from the source system, it needs to undergo the following possible processing steps (not everything is mandatory)
- Transformation: Data transformation to aid in further steps
- Enrichment: Supporting data from lookups to enrich the event.
- Rule Engine: Business rules engine like Drools will help here to execute rules.
- Persistence: Persisting transformed/enriched and processed event for audit
The below mentioned are not exhaustive list of technologies but primary ones that are used for stream processing:
Spark
Distributed stream and batch processing engine that operates on micro-batches of records/events that are to be processed. Rich set of APIs available and have libraries for ML and graph processing as well. Very powerful architecture and processing performance is very high. There could be inherent latency due to microbatches.
Flink
Stream processing engine that is highly performant and efficient. Flink acts on every event as and when it occurs and not on micro-batches like spark. Hence it is highly performant and can achieve sub second latency.
NiFi
NiFi is a configurable data transportation and processing engine that presents a nice UI that has support for 100s of inbuilt processors and connectors. It is developer friendly and can build data pipelines in minutes. Heavy processing cannot be done like spark and flink and primarily used in industry for light-weight processing.
Things To Note
- Mindful of creation of multiple connection objects to databases as it can quickly get overwhelming.
- Adhering to software design principles (SOLID) when creating applications/services to enable loose coupling and enhance generalization.
- Optimization should come at a later stage. Develop to implement functionalities and then once bottlenecks are identified, concentrate on optimization.
Storage
Storage becomes crucial in streaming architecture both for quicker writes and reads. The events must be persisted at stages in the pipeline to make sure that we have a track of how the events flowed through the pipeline. Suppose if the event gets dropped because of not passing the rule, it needs to be captured as well for audit.
Two types of storage can be thought off here – persistence and caching.
Persistence
Persistence is permanent storage of data that can be used for maintaining history of events and audits. Any application will need some sort of persistence primarily for historical analysis, logging, debugging and auditing purposes. Without persistence, there will be no track of what flew through the system and the data will not be available for future use cases.
Technologies
These are primarily used for persistence as they are highly distributed and have faster reads and writes. NoSQL databases are evaluated based on CAP (Consistent, Availability and Partition Tolerance) mechanism
Hbase
Native to Hadoop ecosystem, highly consistent read and fast writes. Availability is not very high in HBase due to it’s master-slave architecture.
Cassandra
Highly distributed and efficient and have faster reads and writes than HBase. This is eventually consistent unlike HBase but highly available.
DynamoDB (AWS)
NoSQL offering from AWS cloud. AWS manages the infrastructure and makes sure the database is highly available and consistent. It can give millisecond record retrieval performance.
CosmosDB (Azure)
NoSQL offering from Azure. This is similar to DynamoDB and highly efficient and the infrastructure maintenance is taken care of for us.
Choosing the NoSQL database boils down to the requirement in terms of availability, consistency and the performance expected. Also, the availability of suitable connectors to interact with other components of the system will make a huge difference during this selection.
Caching
Caching is ephemeral storage that sits on top of databases to enable very fast sub-millisecond lookups for streaming pipelines. In-memory caching is primarily used to alleviate the load off the database especially for read.
Technologies
Primary use cases for in-memory caching are – session management, query result caching, game leaderboard, Top 10 products every hour and so on. edis and Memcached are popular, open-source, in-memory data stores. that are available in the market.
Redis
Redis has a rich set of features like persistence, pub-sub, complex data structures, geospatial support, etc.,This makes Redis suitable for wider variety of use cases apart from the ones mentioned above like sticky sessions, enable decoupling between services through pub-sub, etc.,
Memcached
Memcached is relatively popular caching storage as well but it is primarily used when the needs are simple and there are no advanced data structures required. The page explains the differences in detail between the two – https://aws.amazon.com/elasticache/redis-vs-memcached/
Things to Note
- Do not use it unless it is absolutely the need. They are used especially for data pipelines that have sub-millisecond latency requirements.
- Most general cases will be able to achieve substantial performance with NoSQL data stores.
- Data modelling of data stores is crucial – Make sure the data can be quickly read from the data store and also easily traceable from consumption layer till source.
Like what you are reading? You would like our free live webinars too. Sign up and get notified when we host webinars =>
Analyze
Traditionally stream processing has been to collect, process, evaluate a set of business rules and send it for consumption for downstream systems. There are very limited insights generated on the fly. With the advent of new tools discussed below, the streaming analytics space has become quite popular and powerful analytics can be generated on the fly. The tools allow us to write SQL on top of streaming data irrespective of the underlying format and can perform analytics like aggregations, joins, windowed calculations etc.,
Applications
There are a wide variety of applications for streaming analytics. Some predominant ones are below:
Anomaly detection
Detect if there is any anomaly in the behaviour of the system signifying faults.
Real-time KPI dashboards
Operational monitoring that helps to track performance real-time.
Security Attacks
DDoS attacks can be tracked based on huge volume of requests and can be prevented.
Targeted Marketing
Analyze customer preference real time and use it for targeted marketing.
Technologies
SparkSQL
SparkSQL allows us to perform any SQL queries on top of structured streams and write it to any compatible sink. The dataframes, which is the high level abstraction in Spark, is optimized for performance and has a rich set of APIs to perform streaming analytics.
KSQL
KSQL is built on top of KStreams by confluent and widely used to write SQL queries on top of continuous streams on Kafka. KSQL has options to create STREAM and TABLE. Below are the examples of STREAM and TABLE created using SQL command.
KSQL Reference – https://github.com/confluentinc/ksql/blob/0.1.x/docs/syntax-reference.md
Things To Note
- Decisions should be made if the analyzed data is required for real-time consumption. In other words, does that analysis form the critical path.
- More often than not, the analysis phase branches out from the critical path that will help to server more use cases like OLAP reporting, historical insights etc.,
- Having said above, there could be use cases like real-time monitoring of security attacks, fraud detection, user behaviour anomalies etc., that will certainly have analysis in the critical path as that information is essential for timely decision making.
Consume
Consumption of streaming data can be from a wide variety of downstream systems apart from the real-time notification, dashboards and such. The data once entered into the data lake must be persisted in suitable form for consumption and ad-hoc querying from OLAP tools as well to get historical insights.
Applications
If the streaming pipeline is powering a medical system that detects the presence of certain disease, then it is imperative to have all the variables that the system is using to make decisions to be captured both for continuous improvement and auditing purposes.
Technologies
The preferred pattern is to have the raw events stored in data lake and then transform the events into an acceptable data model and publish that to Datawarehouse for the BI tools like Tableau, Power BI, Business Objects or any JDBC/ODBC driver compatible applications to consume the data. This will ensure that the data journey is not ended as soon as the streaming use case is completed. Even if there is no pressing need for storing at this point, there should be a plan to capture those events to not miss out crucial insights through any Business Intelligence tools.
Things To Note
- Consumption or Querying pattern must be known to perform efficient data modelling
- Good practice is to gather a bunch of questions that they would want to ask of the data, especially in OLAP space, to assist with efficient data modelling.
- Even if there are no specific details available, it would be better to have general assumptions and store the data in a data lake so that it can be used in future as purpose arises.
Secure
Security is integral for any data platform let alone the streaming data pipeline. In the relational world, the security is inherently built into the databases and the roles that have access to those tables and even the data is encrypted in some forms to mask PII (Personally Identifiable Information). But in the data lakes, which are massive distributed file systems, it is highly important to secure access to those file systems. The row level security is kind of difficult to achieve but care must be taken that no blanket access is provided to any user of the environment.
Applications
Security tools around the Hadoop environment address concerns related to Authentication, Authorization and Auditing. Authentication means to verify that the person is who they say they are. Authorisation is what the person is able to do in the environment and Auditing is to have track of every action performed in the environment. The Hadoop environments are usually Kerberos enabled to perform authentication. Encryption is usually performed on PII fields at rest and over the wire Kerberos cluster is isolated and will be shielded from malicious requests. Two open source Apache projects in security space are – Knox and Ranger.
Technologies
Knox
The Apache Knox Gateway (“Knox”) provides perimeter security so that the enterprise can confidently extend Hadoop access to more of those new users while also maintaining compliance with enterprise security policies. Apache knox sits on top of kerberos and provides an easy access pattern for clients eliminating the need for complex kerberos configuration and authentication. More details can be found here – https://www.cloudera.com/products/open-source/apache-hadoop/apache-knox.html.
Ranger
Ranger is an authorization management system that will provide fine grained access to Hadoop resources like Hive, HBase, Yarn etc., Ranger assumes the user is authenticated to access the cluster and controls the authorization piece of the puzzle. Authorization is important as it will determine what the users are allowed to access even if they are authenticated into the cluster. Ranger policies help to specify fine grained access controls to restrict each of the resources within the cluster for certain users/service accounts.
Things To Note
- Segregation of environments via namespaces – Development, SIT & PROD
- Implementing roles that can provide fine grained access at the table level.
- Care must be taken to ensure that there is minimum access provided to do the duties.
- Encryption of sensitive information via company-wide governed encryption policy.
- No replication of production data into the development environment.
- The performance and load testing must be done in a secured separate environment once the functionality testings are done at the lower environments.
Alright! Now you have all the information you need to make right tool choices and design a right architecture to build production ready streaming application.
Sign up and get notified when we host webinars and post interesting topics like this on our website =>
